
Comment j'ai accéléré de 22x la vitesse de mon script Python

Cet article est le premier d’une série. Nous avons augmenté de 22x les performances de notre script Python, ce qui est honorable, mais peut-être pourrons nous aller plus loin ?

Le problème
J’ai voulu écrire un script qui me permet de détecter quels sont les pixels les plus fréquents sur un ensemble d’images. Est-ce le blanc, le noir, d’autres ?
Lorsque nous travaillons sur un petit volume d’image, ce n’est pas un souci, Mais lorsque le volume d'images augmente, par exemple pour des dizaines d'images, le temps de traitement devient un enjeu significatif.
Nous allons voir dans cet article comment à partir d’un script le plus simple possible mais peu performant, nous pouvons arriver à un script aux performances bien plus élevées.
1) La version naïve
Partons du principe que nous voulons télécharger 200 images, et les analyser pour compter les pixels les plus fréquemment rencontrés. Nous pourrons donc identifier les couleurs dominantes.
Note : Pour garantir une constance dans les résultats lors des benchmarks, j'ai choisi d'héberger les images localement.
De plus, j'ai mis en place un délai artificiel de 100ms pour simuler une connexion à un site distant. Cette simulation nous aide à mieux représenter les conditions réelles d'une application en ligne.
Note : La performance de chaque script a été évaluée dans un environnement contrôlé, sur la même machine et dans des conditions aussi similaires que possible.
Pour cela, j'ai développé un script, qui exécute chaque script à tester 5 fois et mesure le temps d'exécution grâce à la fonction time.perf_counter.
Nous calculons ainsi la moyenne (mean) et l'écart-type (stdev) des temps d'exécution pour obtenir une évaluation précise des performances.
Ces données nous permettent de comparer les scripts de manière plus nuancée et détaillée.
Aussi, nous mettons en avant le temps d'accélération par rapport à la version initiale du script. C'est pourquoi la première version, étant notre point de référence, présente un facteur d'accélération (speedup) de 1x.
Un speedup < 1 signifie donc une dégradation des performances par rapport au script initial.
Voici notre script initial :
Je vous invite à regarder les extraits de code qui vous seront montrés tout au long de cet article et d’essayer d’observer quelles sont les différences entre chaque version. Cela vous donnera une meilleure compréhension globale et vous habituera aux syntaxes utilisées.
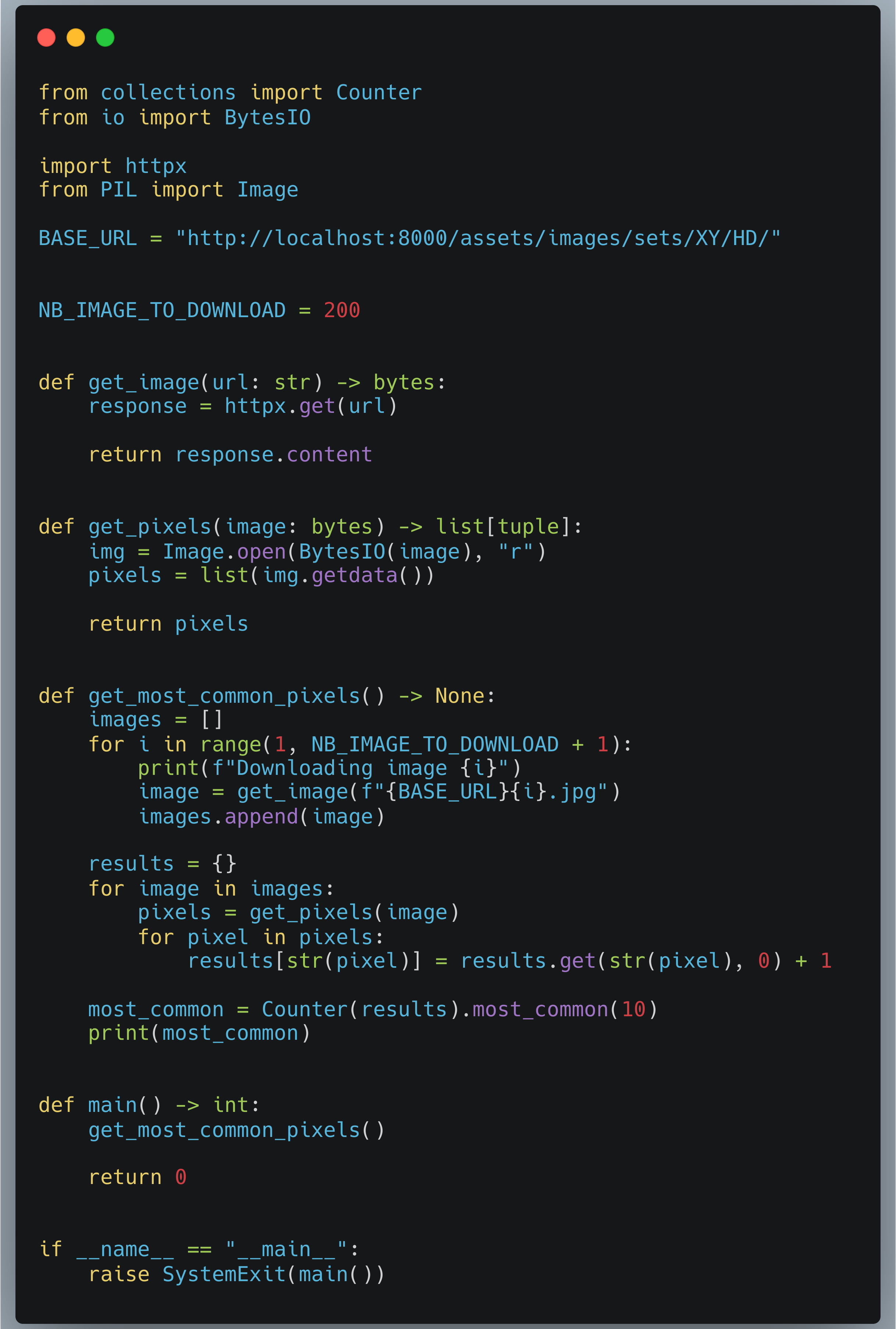
Ce script est certainement la manière la plus naïve d’écrire une solution pour ce problème. On itère sur chacune des URL, on récupère l’image (sans la stocker), et une fois toutes les images acquises, on itère dessus pour comptabiliser les pixels et enrichir un dictionnaire. Ensuite, nous utilisons l’objet Counter du module collections afin d’obtenir les pixels les plus courants.
Lorsque nous mesurons le temps d’exécution de ce script nous constatons :
v1: Mean = 59.17s, Stdev = 9.09s, Speedup = 1.00x
Ce temps semble assez long (pratiquement 1 minute pour traiter 200 images), tentons d’optimiser cela.
2) La version asynchrone
Nous avons vu que la première étape consiste à télécharger des images en masse; c’est typiquement une problématique IO, et les images sont indépendantes les unes des autres. C’est un bon candidat afin d’ajouter de la concurrence.
Nous allons continuer à utiliser le module httpx, mais nous allons l’utiliser en mode asynchrone avec le module asyncio afin de pouvoir envoyer plusieurs requêtes en même temps.
On peut facilement exécuter les 200 coroutines en simultanées grâce à asyncio.gather et récupérer tous les résultats d’un coup.
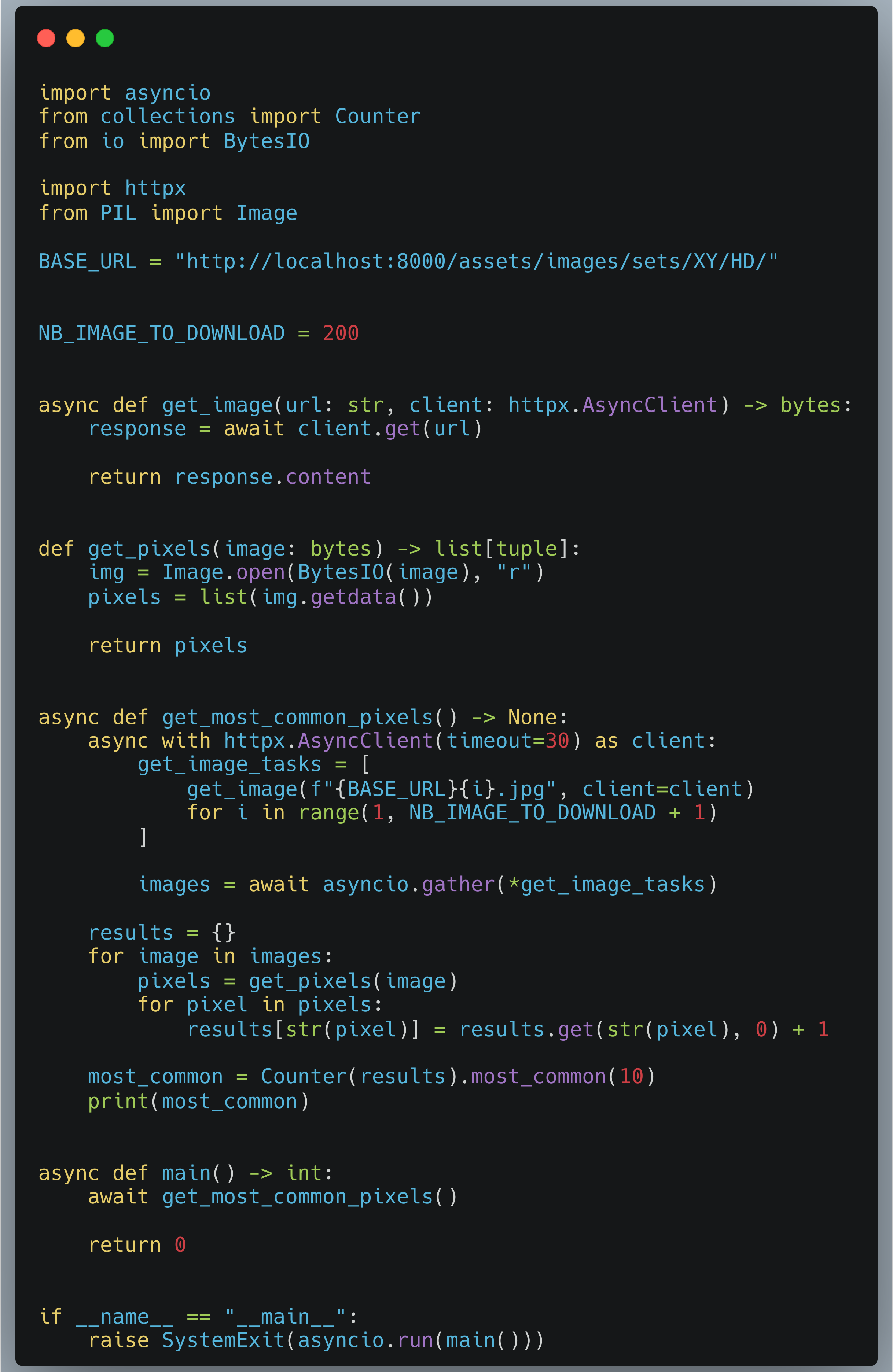
Voici les résultats pour ce script :
tutov2: Mean = 38.85s, Stdev = 0.27s, Speedup = 1.52x
Sans trop de surprises, nous avons gagné ~20 secondes, car il y a 200 images qui répondent avec un délai d’au moins 100ms. Voici un bon début.
Voyons voir si nous pouvons mieux faire.
3) Utilisation de ProcessPoolExecutor
Nous avons réussi à implémenter de la concurrence afin de pouvoir réduire le temps de téléchargement des images. Pouvons_nous faire mieux en rajoutant du parallélisme dans notre programme ?
Lorsque nous parcourons nos pixels et les comptons, c’est une problématique de calcul. Donc CPU et non plus IO. Cette fois asyncio ne nous sauvera pas.
De la même manière le module threading est inadapté aux problématique CPU à cause du GIL (Global Interpreter Lock), qui, pour rappel, empêche plusieurs instructions Python de s’exécuter en même temps au sein d’un même Process.
Ainsi nous allons utiliser le module concurrent.futures, et l’excellent ProcessPoolExecutor qui nous permet de mettre en place du multiprocessing facilement et d’ajouter du parallélisme à notre programme.
Si vous appréciez la newsletter StuffAndCode, vous pouvez vous inscrire afin de ne manquer aucun article !
🐍 Et recevez en PLUS, un article exclusif sur comment profiler n’importe quel type de code Python.
Note : Lorsqu’on démarre un process Python, il y a un main Thread qui s’exécute et le GIL est présent dans chacun des processes. Si nous démarrons plusieurs processes avec un seul Thread, chacun aura son propre GIL. Ainsi, ils ne se gêneront pas ,et nous obtiendrons du vrai parallélisme.
Cependant, démarrer des processes est plus couteux que de démarrer des Threads. De même concernant le transfert des données entre processes.
Voici une implémentation de “comment paralléliser le comptage des pixels sur plusieurs processeurs”.
Nous avons également remplacé le système de dictionnaire pour compter directement avec le Counter.
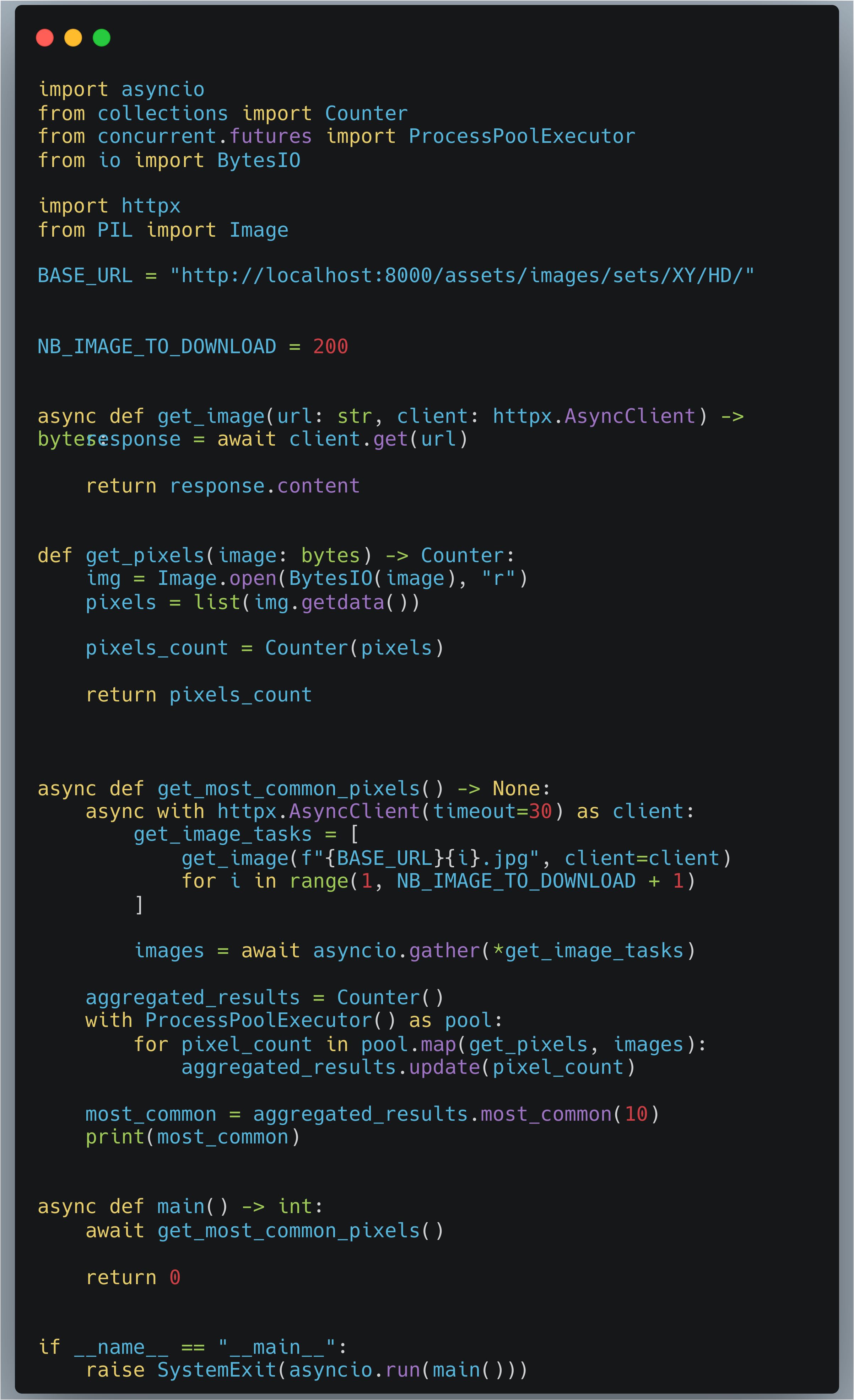
Voici les résultats pour cette version.
tutov3: Mean = 12.01s, Stdev = 0.68s, Speedup = 4.93x
On peut noter une amélioration significative du temps d’exécution.
Nous obtenons 12 secondes contre 59 secondes lors de la première version.
En cas de doute quant à la pertinence de ProcessPoolExecutor ou de ThreadPoolExecutor, sachez que vous pouvez le changer facilement, puis relancer le programme afin de mesurer. Dans mon cas le programme avec le ThreadPoolExecutor prenait 18 secondes au lieu de 12 secondes.
Ce qui signifie que l’ajout du ProcessPoolExecutor est bénéfique.
4) Amélioration de notre Counter
Okay, maintenant qu’on a parallélisé nos téléchargements et nos traitements, quelles améliorations sont possibles ? C’est là qu’il devient intéressant d’ utiliser des outils de profiling, comme détaillé dans cet article.
Si on profile le code précédent (de la partie 3), on remarque que le Counter occupe une part significative du temps de traitement.
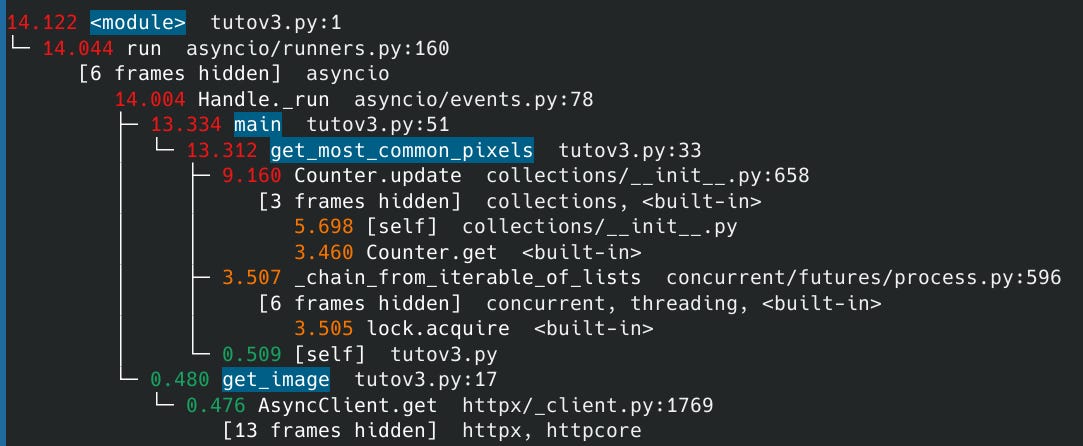
Note : La durée totale de 14.122s ne correspond pas exactement au temps précédent de 12.01s car, dans ce cas, nous avons profilé une seule exécution du code. De plus, le fait de profiler ajoute de l’overhead donc du temps supplémentaire (chose qui n’est pas faite lorsque nous mesurons uniquement le temps d’exécution).
Lorsque nous utilisons notre objet Counter pour compter et récupérer les pixels les plus courants, nous stockons les pixels sous forme de tuple de trois int, RGB. Ce qui n’est pas optimal. Counter fonctionne bien mieux avec des valeurs numériques et plus simples.
C’est pour cela que nous allons ajouter une étape de conversion pour transformer un tuple sous forme (R, G, B) en un entier qui représente cette même couleur.
Pour ce faire, nous allons créer une fonction rgb_to_int qui prend en paramètre un tuple d’int retournant un entier équivalent à ce tuple.
Pour ceux qui s'intéressent aux détails techniques de la conversion de RGB à un entier, voici une explication. Il est important de noter que, dans notre optimisation, nous remplaçons les tuples RGB dans notre Counter par de simples entiers.
4.1) Transformation d’un tuple RGB en entier
Laissez-moi vous montrer comment une petite modification peut engendrer une grande différence.
On va prendre l’exemple de la couleur rose représentée par le code RGB (255, 0, 255).
Conversion de RGB à Int :
RGB : (255, 0, 255)
En binaire, cela donne : R = 11111111, G = 00000000, B = 11111111
Ensuite, on décale ces valeurs :
R décalé de 16 bits (<< 16) devient 111111110000000000000000
G décalé de 8 bits (<< 8) reste 0000000000000000
B reste inchangé : 11111111
On combine ces valeurs pour obtenir : 111111110000000011111111 en binaire
Ce qui donne en entier : 16711935Pour simplifier, on prend chaque composante de couleur, et on la décale pour former un seul nombre. Ce nombre unique représente notre couleur originale. Cela ressemble à la manière dont on gère les permissions sur Linux : Read (4), Write (2), Execute (1). Lorsqu'on veut toutes les permissions, on utilise le chiffre 7, qui est la somme de 4, 2 et 1.
Le principe du décalage en binaire, comme dans l'opération « 1 << 2 », signifie que l'on prend le nombre 1, le convertit en binaire (0001), et décale ses bits de deux places vers la gauche. Ainsi, 0001 devient 0100, ce qui équivaut à 4 en décimal.
Le code qui correspond à cette opération est celui-ci :

4.2) Transformation de l’entier vers le code RGB
Lorsque nous voulons afficher les résultats, nous cherchons à retrouver le code RGB initial. Donc, il nous faut un moyen d’inverser le calcul que nous avons fait. Voici comment cela fonctionne:
Le masquage binaire est une opération qui permet d'isoler certains bits dans un nombre binaire. Dans le cas de la fonction int_to_rgb, le masque & 0xFF est utilisé pour extraire les 8 bits les plus bas d'un entier. Le masque 0xFF est de l’hexadecimal et est équivalent à 11111111 en binaire. Ce qui signifie qu'il conserve les 8 bits avec lesquels il est comparé et met tous les autres à zéro.
Entier : 16711935
Binaire : 111111110000000011111111
Extraction de Rouge (R) :
Décalage : >> 16 donne 11111111
Masque : 11111111 & 11111111 = 11111111
Résultat : 255 (en décimal)
Extraction de Vert (G) :
Décalage : >> 8 donne 0000000011111111
Masque : 00000000 & 11111111 = 00000000
Résultat : 0 (en décimal)
Extraction de Bleu (B) :
Pas de décalage
Masque : 11111111 & 11111111 = 11111111
Résultat : 255 (en décimal)
RGB : (255, 0, 255)Lorsque nous faisons du développement web, ou autre, nous ne sommes pas souvent confrontés à cette syntaxe. Aussi un peu de pratique peut être bénéfique. Le mieux est de démarrer un interpréteur Python et de faire quelques tests.
Le code représentant l’opération de transformation d’entier vers RGB est celui-ci :

Fin de la parenthèse.
Voyons le code complet.
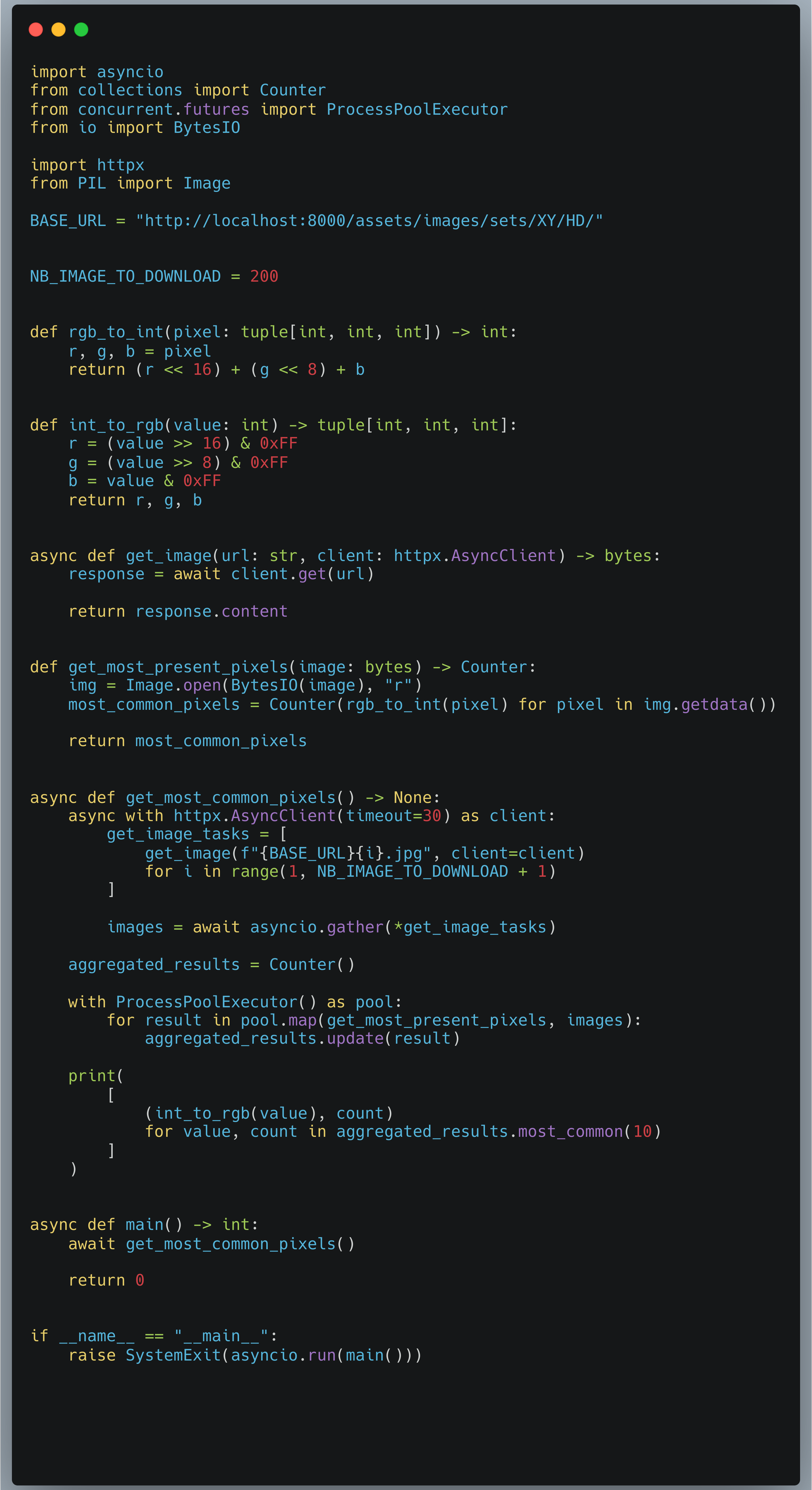
Voici le résultat pour ce script :
v4: Mean = 7.80s, Stdev = 0.61s, Speedup = 7.58x
Wow, le temps est bien réduit rien qu’avec cette modification.
Je n’aurai pas pensé que le type de données utilisées par Counter pourrait avoir une influence aussi grande.
5) Traitement par batch
Nous l’avons évoqué précédemment, nous avons besoin de plusieurs processes afin de paralléliser les calculs, car sinon cela prendrait trop de temps sur un seul processeur.
Cependant, le fait de compter les pixels n’est pas si long que ça. Démarrer un nouveau process et faire transiter les data est coûteux.
Ne serait_il pas possible de faire quelque chose à ce niveau ?
Pourquoi ne pas traiter plusieurs images d’un coup, puis mettre à jour un Counter pour un batch d’images ?
La mécanique reste la même, nous spawnons toujours autant de processes (les Process ne sont créés qu’une fois et réutilisés grâce au ProcessPoolExecutor), nous allons traiter plusieurs images d’un coup. Donc réduire le nombre de réutilisations de chaque process et aussi réduire le nombre de données qui doivent passer du process au main process pour avoir les résultats finaux.
Car au lieu d’envoyer 200 (nombre d’images) fois des Counter, nous allons en envoyer plus que 20 (pour des batchs de 10 images). Ce qui évite la procédure de pickling et unpickling qui consomme également du temps.
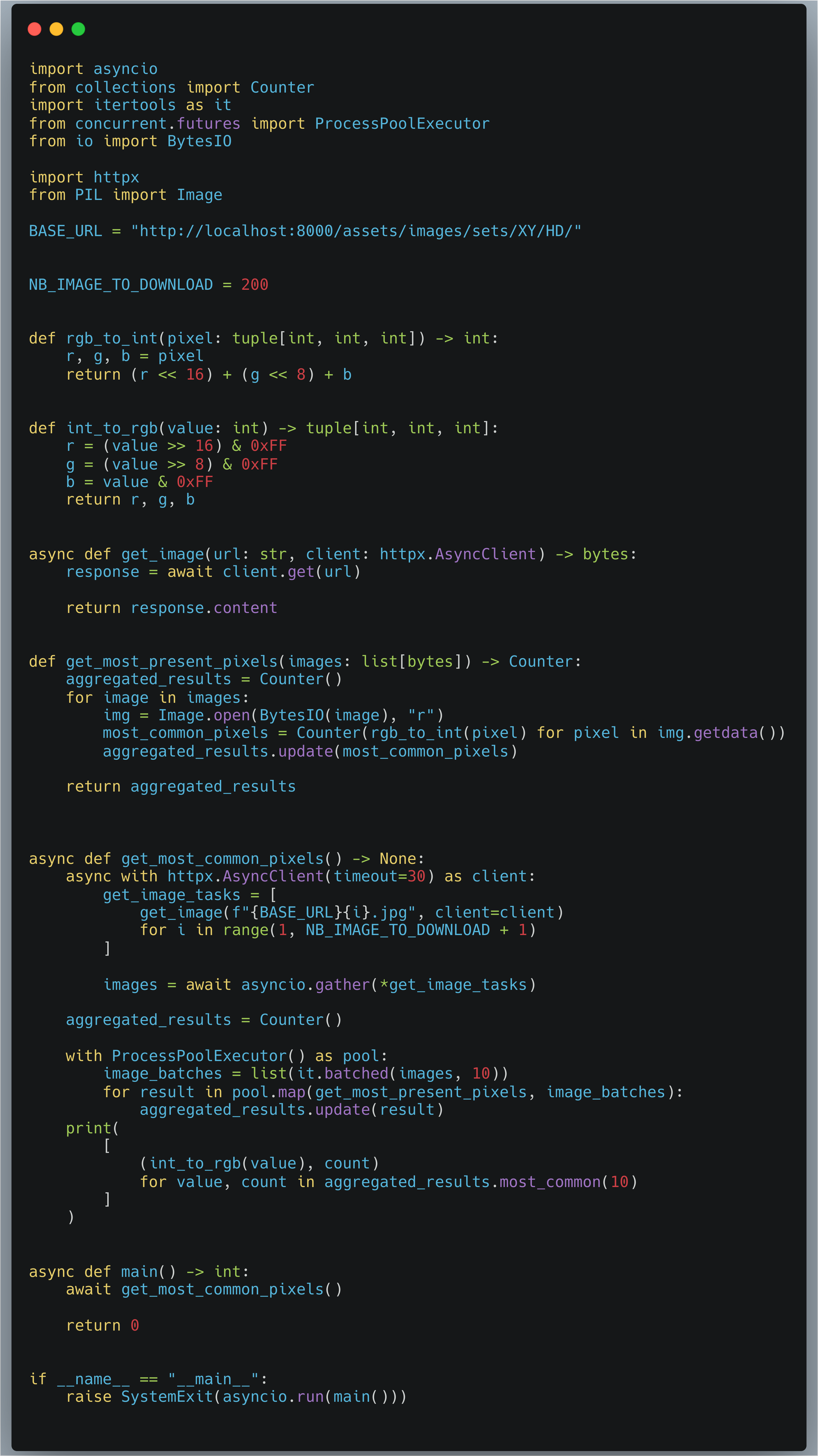
Voici les résultats pour cette version :
v5: Mean = 2.67s, Stdev = 0.03s, Speedup = 22.20x
2.67s pour télécharger et traiter les 200 images, contre 59s à la base, c’est pas trop mal.
Nous avons donc accompli encore un joli pas en avant.
Le choix du nombre 10 pour les batches est arbitraire. Il est conseillé d'expérimenter avec différentes tailles de batch pour trouver le nombre le plus optimal, en augmentant ou diminuant cette valeur.
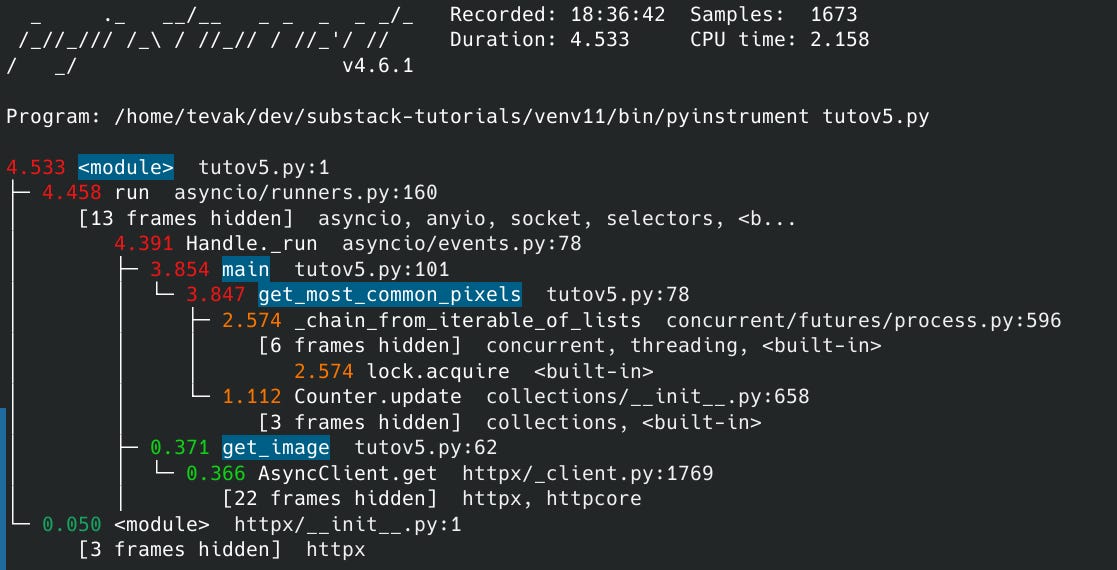
Voici le profiling.
Comme précédemment, les résultats sont différents en raison de l'overhead du profiling. Nous pouvons donc voir qu'il y a du temps passé dans le multiprocessing et également que nous passons encore pas mal de temps dans le Counter.update.
Nous verrons si nous pouvons améliorer ces performances dans un prochain article !
Les résultats
Si on compare les résultats de toutes nos versions, nous obtenons ceci :
Results:
v1: Mean = 59.17s, Stdev = 9.09s, Speedup = 1.00x
v2: Mean = 38.85s, Stdev = 0.27s, Speedup = 1.52x
v3: Mean = 12.01s, Stdev = 0.68s, Speedup = 4.93x
v4: Mean = 7.80s, Stdev = 0.61s, Speedup = 7.58x
v5: Mean = 2.67s, Stdev = 0.03s, Speedup = 22.20x
Les prochaines étapes ?
Il existe d'autres optimisations que nous pourrions explorer.
Par exemple, envisager d'utiliser des bibliothèques comme Numpy ou Polars, qui exécutent du code en C et Rust respectivement. Ces outils sont spécialement optimisés pour le traitement efficace de données volumineuses.
Nous pourrions aussi choisir d'exécuter notre code sur une autre implémentation de Python que CPython (qui est l'implémentation standard de Python). Des alternatives comme PyPy ou IronPython peuvent offrir des avantages en terme de performances pour certains types de tâches.
Une autre stratégie consiste à écrire certaines parties critiques de notre code en C, Cython ou Rust.
Et bien sûr, il y a sûrement d'autres méthodes d'optimisation à découvrir et à expérimenter.
Mais ça, nous le garderons pour une prochaine fois !
Si vous appréciez la newsletter StuffAndCode, vous pouvez vous inscrire afin de ne manquer aucun article !
🐍 Et recevez en PLUS, un article exclusif sur comment profiler n’importe quel type de code Python.
Je m’intéresse aussi beaucoup à l’optimisation de mes applications. J’aime beaucoup ta démarche. Ça fait longtemps que t’es là dedans ?
Si t’as le temps ça m’intéresserait de savoir quels sont les avantages spécifiques de l’utilisation du ProcessPoolExecutor pour le traitement des pixels dans les images, et comment se compare-t-il aux méthodes asynchrones et séquentielles utilisées précédemment dans ton script ?