
Les différents types de profilers et les mesures de temps


1) Les types de profilers
Il existe deux types de profiling couramment utilisés en Python : le Deterministic Profiling et le Statistical Profiling.
Note : Ici, on ne parle pas de profiling de mémoire mais uniquement de profiling de performances.
1.1) Deterministic Profilers

Les profilers déterministes, tels que cProfile, tracent et mesurent tous les appels de toutes les fonctions. Cette approche fournit des données détaillées sur chaque fonction appelée.
Nous pouvons avoir plusieurs informations grâce à ce type de profiling :
Nombre d'appels (ncalls) : cProfile affiche le nombre total d'appels pour chaque fonction sous la colonne 'ncalls'. Cela inclut les appels directs et récursifs.
Temps total par fonction (cumtime) : Sous la colonne 'cumtime', cProfile indique le temps cumulatif passé dans la fonction et toutes les fonctions qu'elle appelle.
Temps propre par fonction (tottime) : Le temps propre, indiqué dans la colonne 'tottime', représente le temps passé uniquement dans la fonction elle-même, excluant le temps passé dans les fonctions appelées.
Appels récursifs (ncalls) : Les appels récursifs sont également inclus dans 'ncalls'. Les appels récursifs sont souvent indiqués sous une forme '3/1', où le premier nombre est le nombre total d'appels et le second le nombre d'appels récursifs distincts.
Ordre d'appel : L'ordre d'appel n'est pas directement visible dans les rapports standards de cProfile, mais des outils de visualisation tel que SnakeViz peuvent être utilisés pour voir l'ordre d'appel des fonctions.
Bien que le profiler puisse introduire un certain overhead, il reste utile pour l'identification des bottlenecks dans les programmes. Nous combinons souvent cProfile avec d'autres outils, comme des outils de visualisation pour interpréter les résultats si jamais le profiling est complexe.
L’overhead, quèsaco ?
L'overhead, en profiling, est le coût supplémentaire en termes de performance que votre programme doit supporter lorsqu'il est analysé par un profiler.
Prenons un exemple concret : si vous utilisez un profiler déterministe comme cProfile en Python, il va enregistrer des détails sur chaque appel de fonction et chaque opération dans votre programme.
Bien que cette information soit précieuse pour l'optimisation, le processus d'enregistrement lui-même nécessite des ressources supplémentaires - utilisation supplémentaire du processeur, consommation de mémoire, etc.
Cela signifie que votre programme, lorsqu'il est profilé, va probablement s'exécuter plus lentement et utiliser plus de ressources qu'en temps normal.
Ce ralentissement et cette consommation accrue sont ce qu'on appelle l'overhead. Il est important de tenir compte de cet overhead lors de l'analyse des résultats du profiler, car il peut fausser la perception des performances réelles du programme.
En bref, il est important de prendre en compte que l'overhead représente le coût en performance dû au processus de profiling lui-même.
1.2) Statistical Profilers
Les profilers statistiques, comme py-spy ou pyinstrument, adoptent une approche différente. Plutôt que d'enregistrer chaque appel de fonction, ils enregistrent la call stack à intervalles réguliers. Cette méthode génère moins d'overhead, ce qui est avantageux pour les applications en production où minimiser l'impact sur les performances est crucial.
La call stack est une structure de données qui permet de stocker des informations sur les instructions de notre programme qui sont en cours d’execution.
Plus d’informations ici

Bien que les profilers statistiques fournissent une vue d'ensemble utile, ils peuvent parfois manquer de certains détails fins que les profilers déterministes révèlent.
Ils sont particulièrement adaptés pour obtenir un aperçu global des performances d'une application, et pour identifier les zones où le temps est principalement consacré.
Si vous appréciez la newsletter StuffAndCode, vous pouvez vous inscrire afin de ne manquer aucun article !
🐍 Et recevez en PLUS, un article exclusif sur comment profiler n’importe quel type de code Python.
2) Les mesures de temps
2.1) CPU Time
Le CPU time correspond au temps durant lequel le CPU est occupé à exécuter du code. Par exemple, si vous avez une fonction qui envoie une requête à un site web et attend la réponse pour renvoyer le HTML, la majeure partie du temps sera passée en attente de la réponse du site, et non dans l'exécution de votre code proprement dit. Ainsi, le CPU time enregistré sera relativement faible.
2.2) Wall Clock Time
Le wall clock time, quant à lui, se mesure comme si on le faisait en regardant une montre. Il est particulièrement utile pour évaluer les performances d'applications qui interagissent beaucoup avec d'autres services, ou qui effectuent des appels à des API. Cette mesure permet de déterminer si la lenteur de l'application est due à votre code ou à l'attente de réponses externes.
Exemple : Mesurer le CPU time et le Wall clock time d'un script Python
Prenons un script Python basique, dummy.py, qui télécharge un gros fichier :
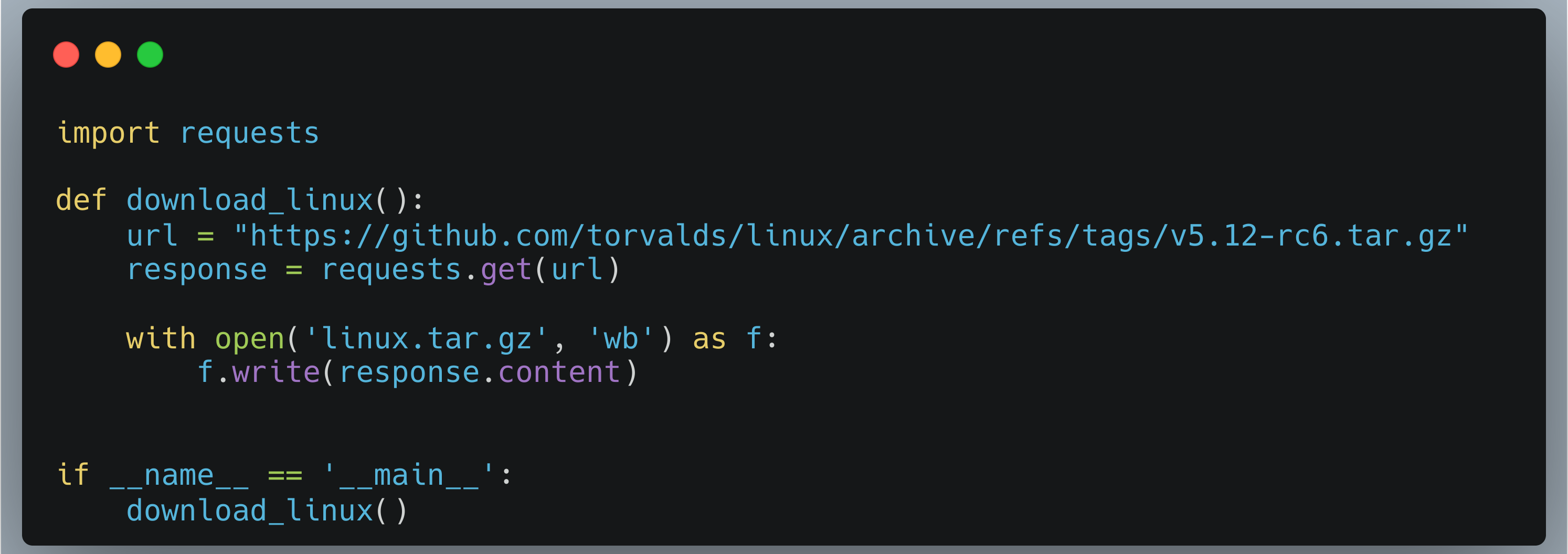
Nous pouvons mesurer le CPU time et le Wall clock time avec la commande Linux time.
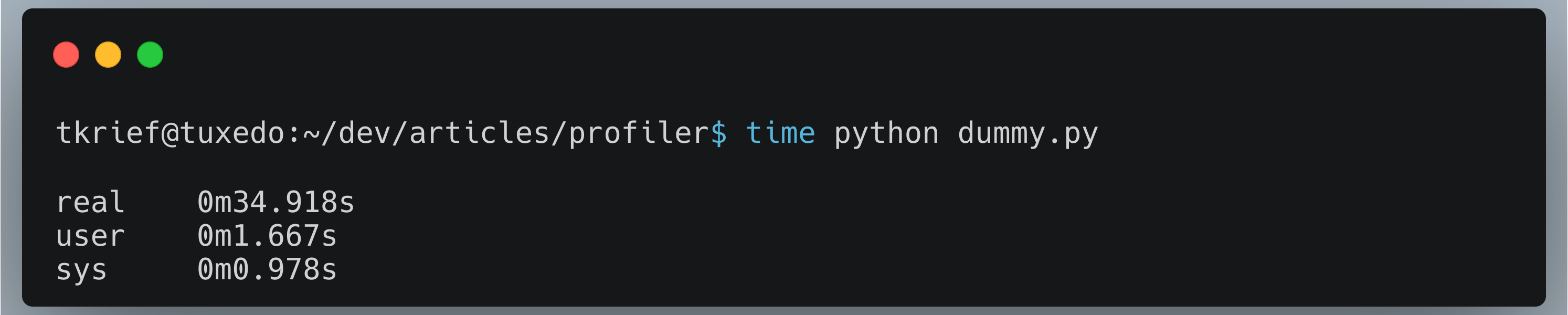
Ici, real représente le temps total écoulé depuis le lancement jusqu'à la fin de l'exécution du script (Wall clock time).
User est le CPU time utilisé par le processus utilisateur (User CPU time).
Sys indique le CPU time utilisé par le système pour des tâches au niveau du kernel, telles que l'écriture de fichiers ou l'allocation de mémoire. Plus de détail sur cette réponse de StackOverflow :
Explication real, user, sys de la commande time
Dans cet exemple, la majorité du temps est consacrée à attendre la réponse du serveur (I/O), plutôt qu'à l'utilisation du CPU. Sur35 secondes environ d'exécution du script, seulement 2.6 secondes environ (user + sys) sont consacrées à des tâches CPU. Cela indique que pour optimiser ce code, il faudrait se concentrer principalement sur la partie réseau.
Les résultats
Nous allons profiler un script très simple afin de montrer les résultats que nous pouvons obtenir avec cProfile et pyinstrument, pour présenter un cas concret et expliquer comment interpréter les résultats.
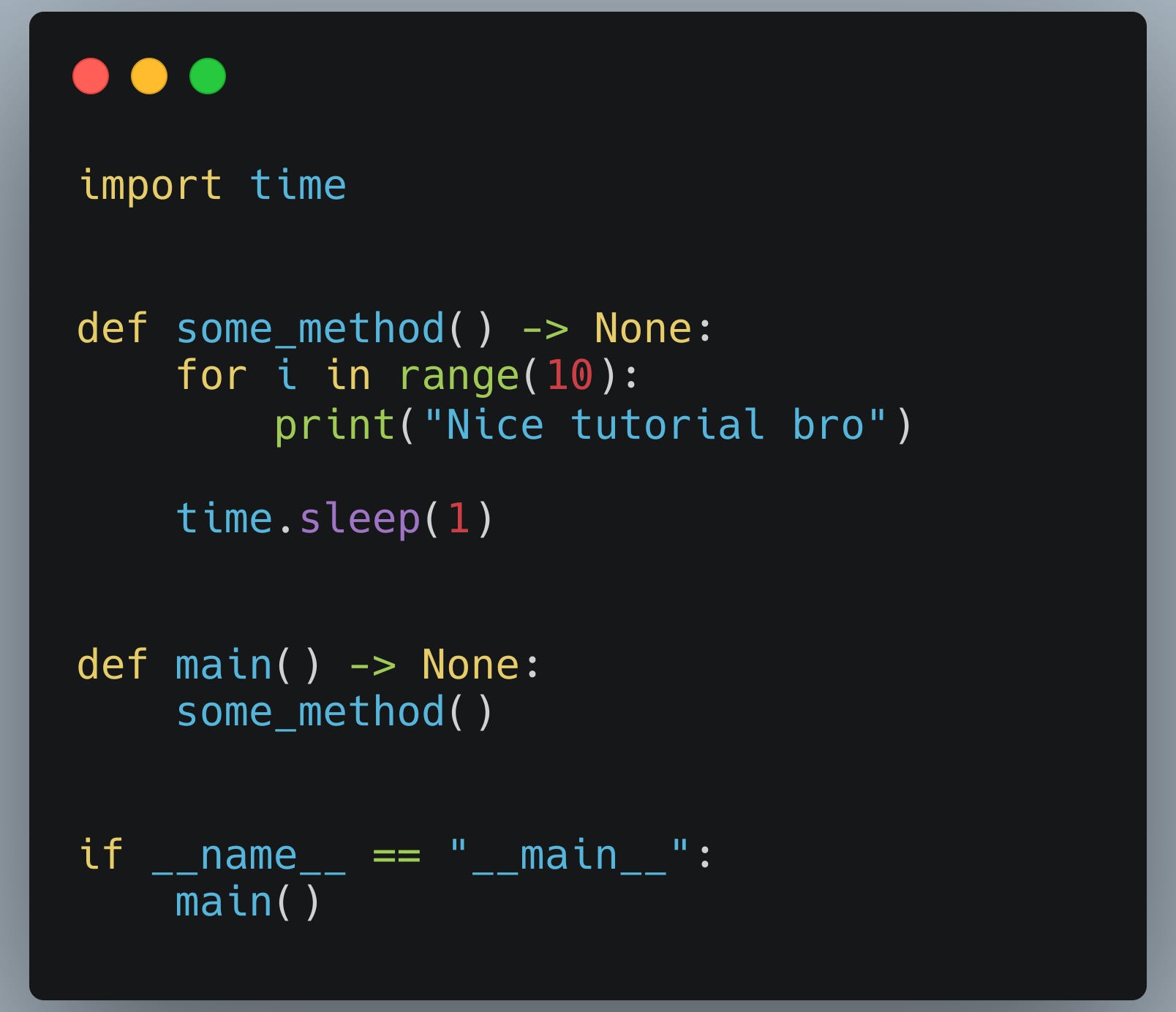
Voici le code en question, une boucle avec des prints et un time.sleep.
Quelque chose de simple mais qui va pouvoir illustrer nos propos.
cProfile
Afin de profiler notre programme, nous pouvons utiliser la commande suivante :
python -m cProfile -s cumtime some_script.py
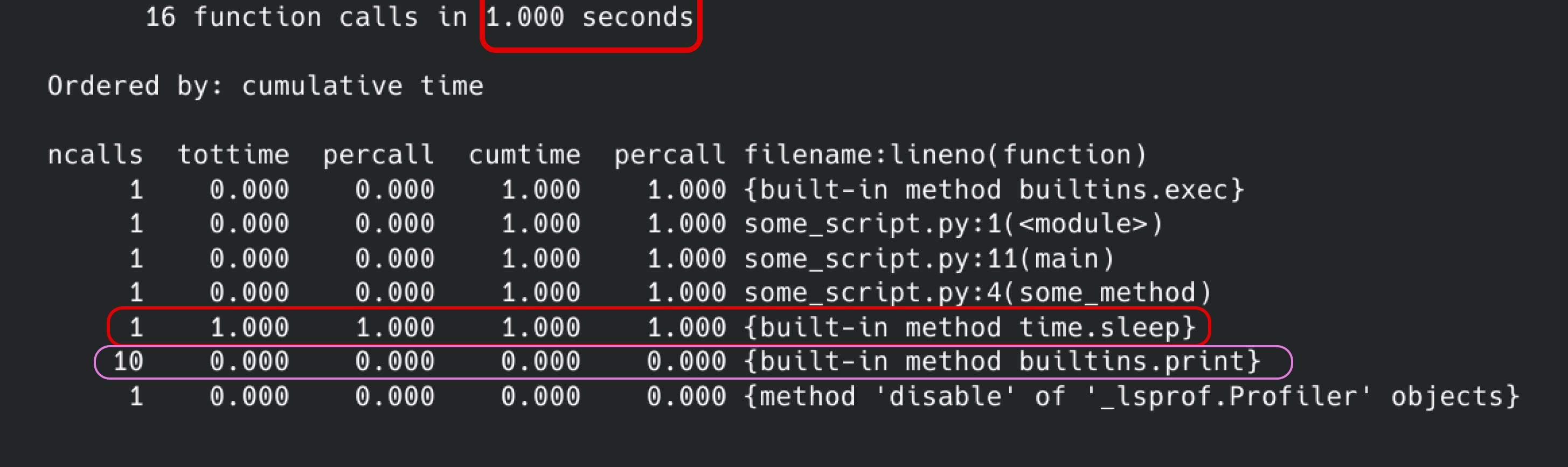
Nous pouvons voir que le script prend 1 seconde, donc ceci est un wall clock time ainsi que les endroits qui prennent le plus de temps. Par exemple, nous pouvons voir que time.sleep est la méthode qui prend le plus de temps (cf. la colonne tottime).
Aussi, nous pouvons observer que la fonction print a été appelée 10 fois. Nous pouvons changer l’ordre de cet output en fonction de ce que nous voulons examiner.
Nous pouvons également utiliser des outils de visualisation afin d’avoir un rendu plus graphique, mais ce n’est pas l’objet de cet article.
PyInstrument
Passons maintenant à pyinstrument. Pour l’installer, vous pouvez executer la commande :
pip install pyinstrument
et puis commencer le profiling :
pyinstrument some_script.py
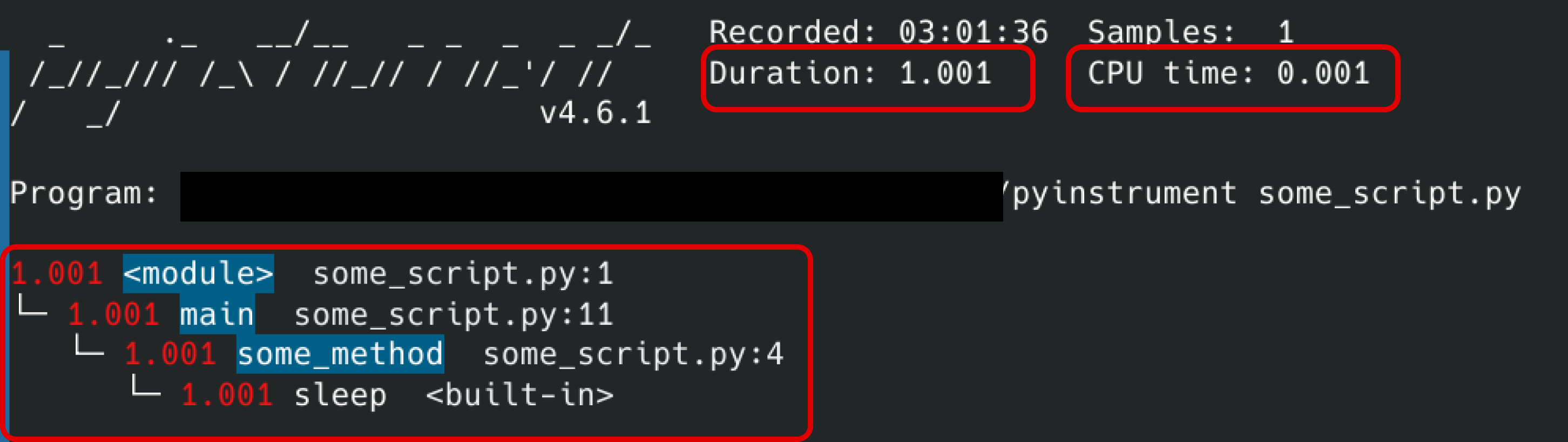
Sur ce screenshot, nous pouvons constater plusieurs choses :
tout d'abord, nous avons la durée qui est le wall clock time ainsi que le CPU time.
Nous pouvons également remarquer que le CPU time est vraiment très court comparé au wall clock time, ce qui signifie que le CPU a été en attente pendant la quasi-totalité du programme.
Enfin, nous pouvons visualiser les méthodes qui prennent le plus de temps sous forme d’arbre, c’est assez pratique. Il peut y avoir plusieurs branches qui indiquent ce qui prend le plus de temps et permettent de savoir l’origine de l’appel.
Quizz Time
Je trouve qu’il est toujours pertinent de se remémorer ce qu'on vient de lire, pour vérifier si l’on a vraiment retenu quelque chose.
Voici quelques questions :
Quels sont les différents types de profilers ?
Quelles sont leurs différences ?
Pouvez-vous nommer un profiler de chaque type ?
Quelle est la différence entre wall clock time et CPU time ?
Si vous avez tout juste, vous avez compris l'essentiel de cet article, bien joué !
Si vous appréciez la newsletter StuffAndCode, vous pouvez vous inscrire afin de ne manquer aucun article !
🐍 Et recevez en PLUS, un article exclusif sur comment profiler n’importe quel type de code Python.
Super article ! Fluide, facile à lire et à intégrer, je sens que je peux vraiment step up en Python avec des articles de ce genre
Keep up the good work 👍🏻
Pas mal du tout ! C'est fluide à lire c'est cool. ET enfin de la doc Python pertinente et approfondie en FRANCAIS ! Merci continue