
Accélérer nos tests Python avec la parallélisation
Pourquoi ? Comment ? Faut-il toujours paralleliser nos tests ?


Dans le développement, la mise en place de tests est une étape incontournable.
Qu'ils soient unitaires, fonctionnels ou end-to-end, les tests garantissent la qualité et la fiabilité du code. Cependant, à mesure que notre codebase s'élargit, le nombre de tests augmente, entraînant une augmentation significative du temps de test.
Cette situation a deux conséquences principales :
une perte de temps directe pour le développeur.
dans le cas de pipelines de CI, des coûts accrus liés au temps d'exécution des tests.
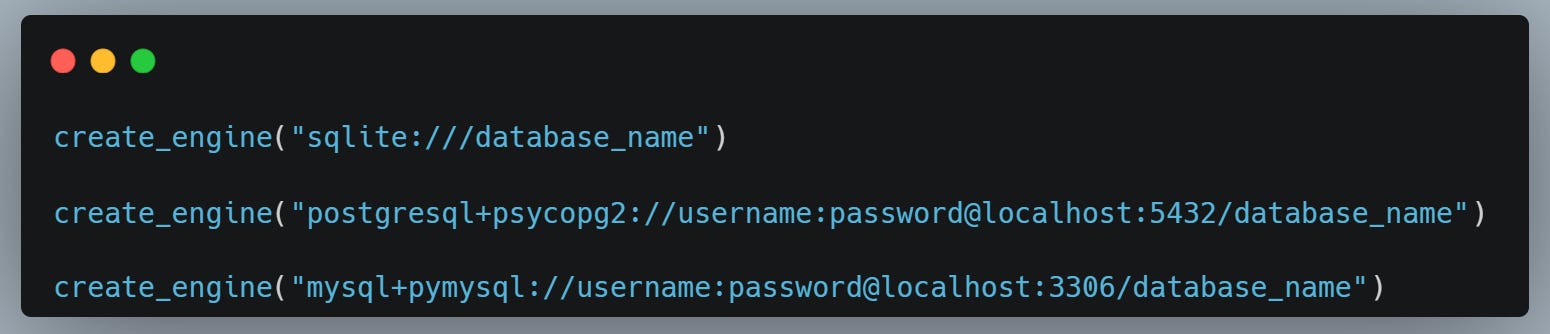
⚠️ Dans cet article, nous allons utiliser SQLlite en tant que base de données, mais cela fonctionne de la même manière si vous utilisez une autre base de données tels Postgres ou MySQL ou autre.
Il suffit de changer l’URL lors de la création de l’engine SQLAlchemy. Par exemple :
Accélérer les tests
Plusieurs stratégies peuvent être adoptées.
Par l'optimisation des tests eux-mêmes, en observant ce qui prend du temps, peut-être même revoir le scope des fixtures etc… Mais cette approche a plusieurs limites, dont la première : si le code à tester est long, malgré l’optimisation des tests, il y aura peu de différence.
La méthode la plus simple et la plus efficace semble être la parallélisation des tests. L'idée est de lancer plusieurs tests simultanément au lieu de les exécuter les uns aprés les autres.
Parallélisation avec Pytest-xdist
Pytest-xdist est un outil Python qui facilite cette parallélisation. L'utilisation de cet outil est simple : si vous disposez de 32 CPU, vous pouvez théoriquement exécuter jusqu'à 32 tests simultanément.
Cette capacité à exécuter des tests en parallèle peut grandement améliorer le temps nécessaire pour lancer votre suite de tests.
De plus, la mise en place est très facile :
>> pip install pytest-xdist
>> pytest -n autoLa commande pytest -n auto va détecter automatiquement votre nombre de CPU afin de pouvoir créer le nombre approprié de workers ,et démarrer les tests sur ceux-ci.
Les side-effects et la parallélisation
Cependant, la parallélisation soulève un défi de taille : la gestion des side effects. Certains tests peuvent modifier des ressources externes, comme des fichiers ou des bases de données, polluant ainsi les l’environnements pour d'autres tests.
Par exemple, un test créant des instances dans une base de données peut laisser des traces qui affecteront les tests suivants.
C’est un problème connu : lorsqu’on execute des tests qui se servent d’une base de données, nous devons nettoyer cette base de données entre chaque test.
Nettoyer sa base de donnée après chaque test
Pour remédier à cela, deux approches principales sont souvent utilisées :
l'utilisation de rollbacks en fin de test
la suppression de la base de données après chaque test.
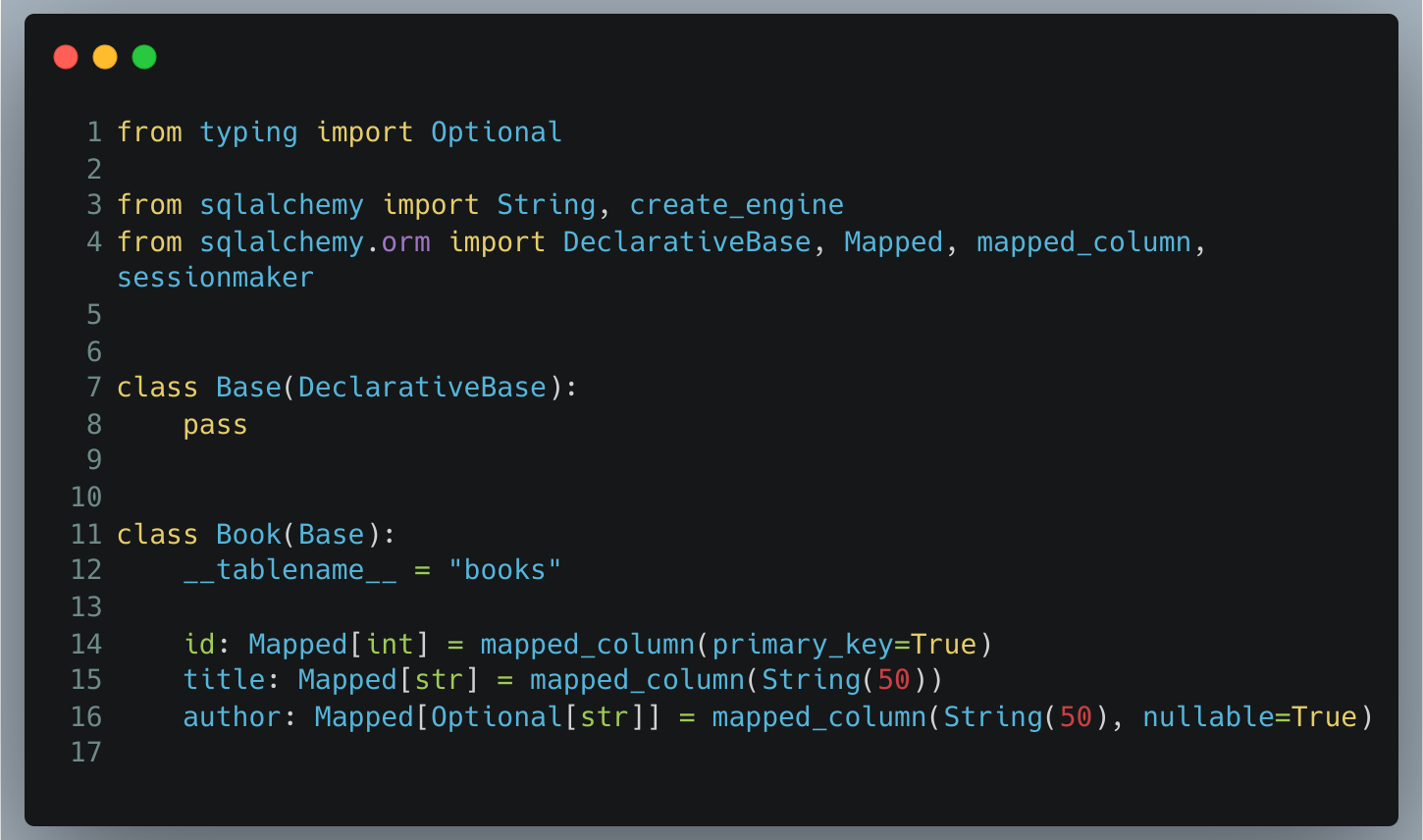
Afin d’illustrer nos exemples, nous allons partir du model SQLAlchemy que nous désirons tester :
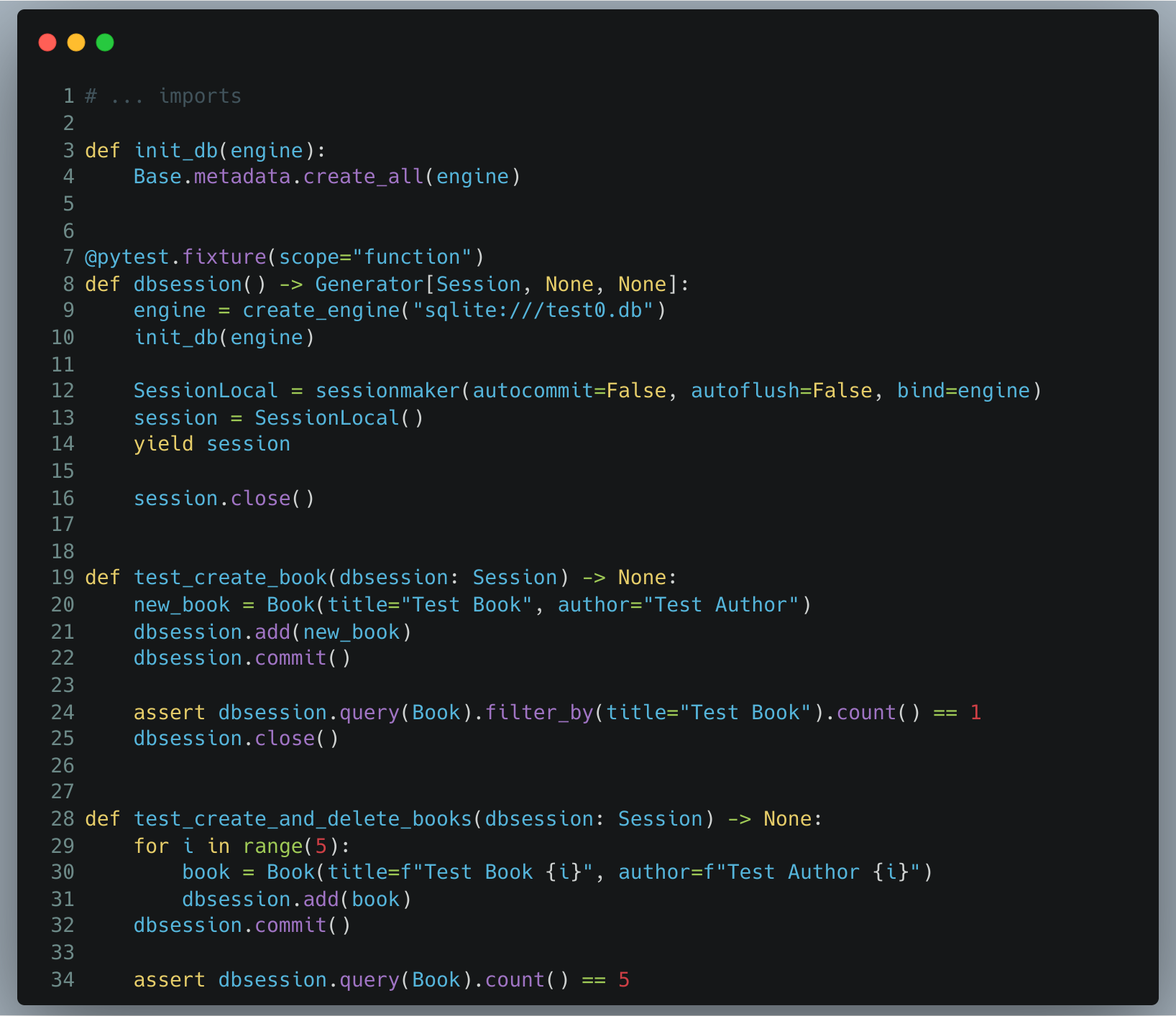
1) Tests sans nettoyage des données
Nous avons deux tests : un qui crée un Book et qui vérifie qu’il existe bien un seul Book; un second test qui crée 5 Books et qui vérifie qu’il en existe 5. Ces tests sont simples mais ils vont permettre d’illustrer nos propos.
Si j’execute de manière séquentielle (l’un aprés l’autre) mes tests, je vais d’abord créer 1 Book . Le test va passer. Mais lors du deuxieme test, je vais créer 5 books supplémentaires, sans avoir nettoyé ma base de données, en supprimant le book de l’ancien test. Par conséquent, au lieu d’avoir 5 books j’en aurai 6.
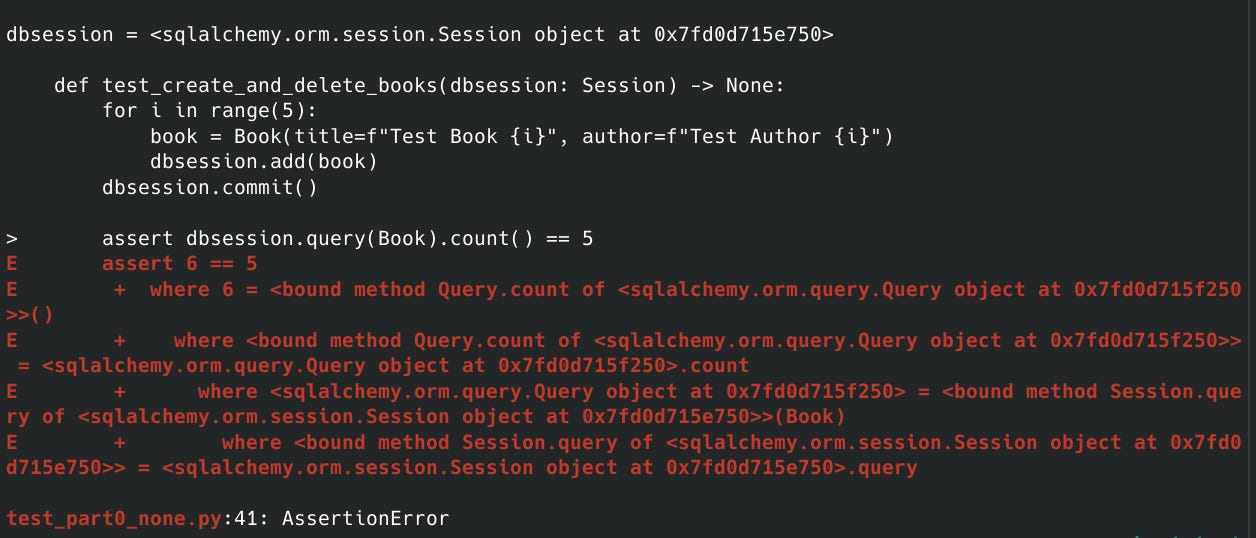
Donc, il nous faut un moyen de remettre notre database en état entre chaque test pour éviter les pollutions.
2.1) Utilisation de rollback à la fin du test
Afin d’éviter la pollution de test, une solution souvent préconisée est de réaliser un “rollback” à la fin de notre test, de sorte que toutes les actions réalisées dans la transaction courante soient annulées.
On peut donc ajouter ce comportement directement à notre fixture.
Essayons ce code ci :
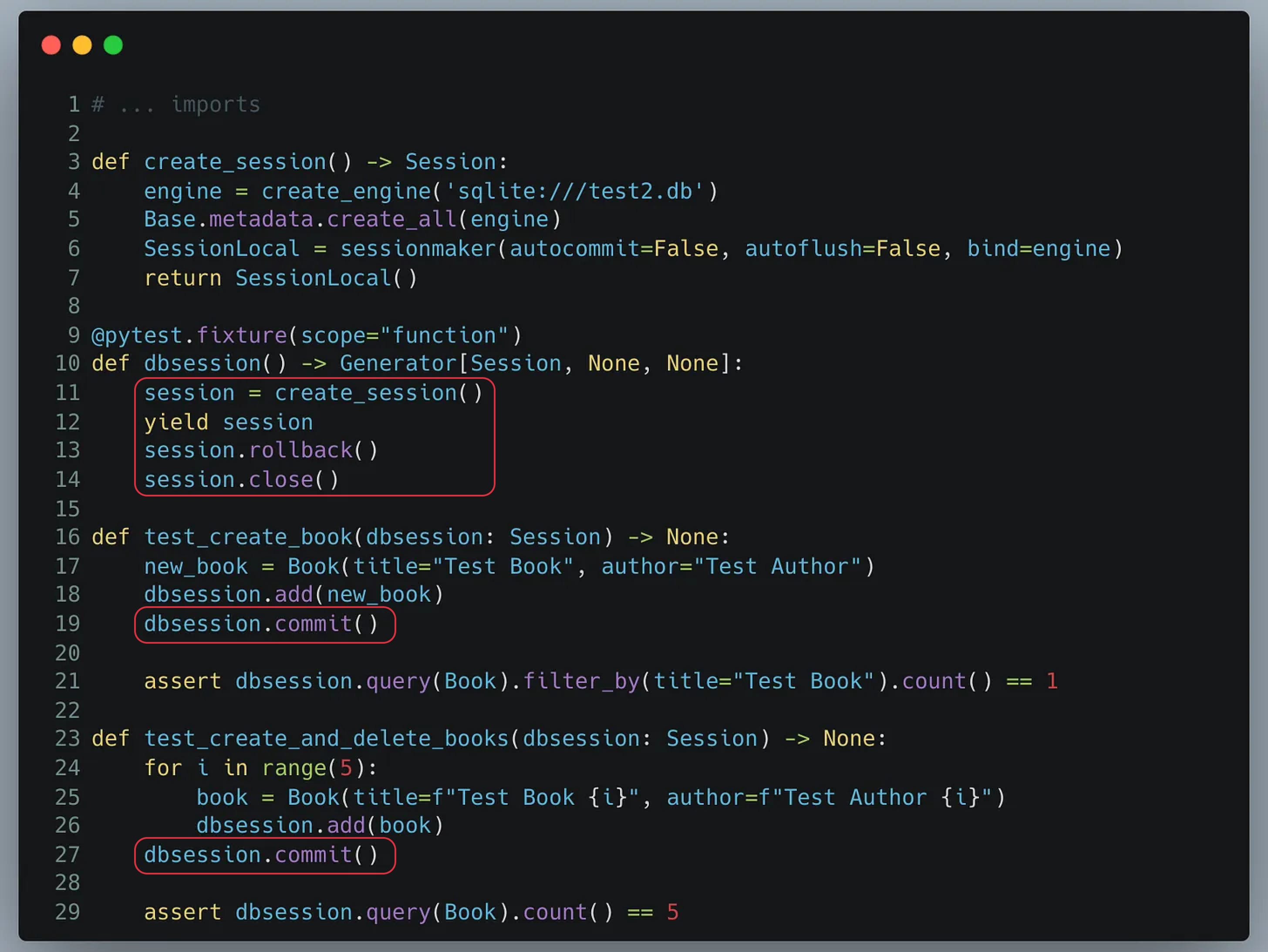
Voici les résultats de ces tests :
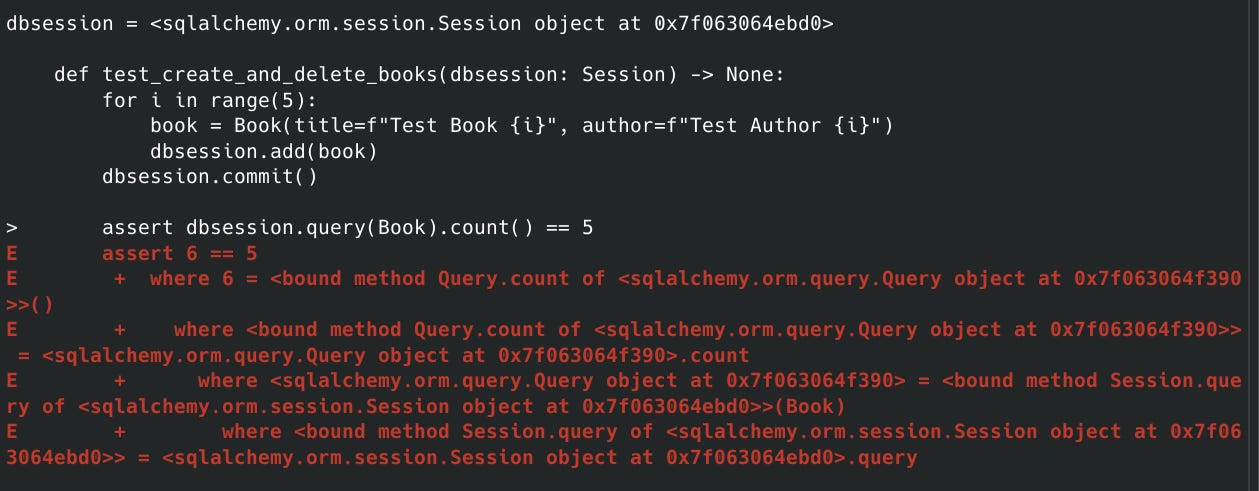
Comme vous pouvez le constater, les tests ne passent pas. Pourquoi ?
Tout simplement parce que, même si nous faisons un “rollback” à la fin du test dans notre test, apparaissent des commits pour seeder nos tests, et donc ces changements sont persistés en base de données au moment du commit.
Ainsi, dès que le test fait un commit, le rollback n’aura plus d’effet car les résultats auront déjà été persisté en base de données.
2.2) Un hack pour rollback
Il existe effectivement un “hack” pour rollback entre chaque test.
Mais ceci dépasse le scope de cet article. Je vous renvoie à l’article qui l’aborde en cliquant ici.
Pour plus de détails, vous pouvez directement vous rendre sur la page de SQLAlchemy qui détaille son fonctionnement en suivant ce lien.
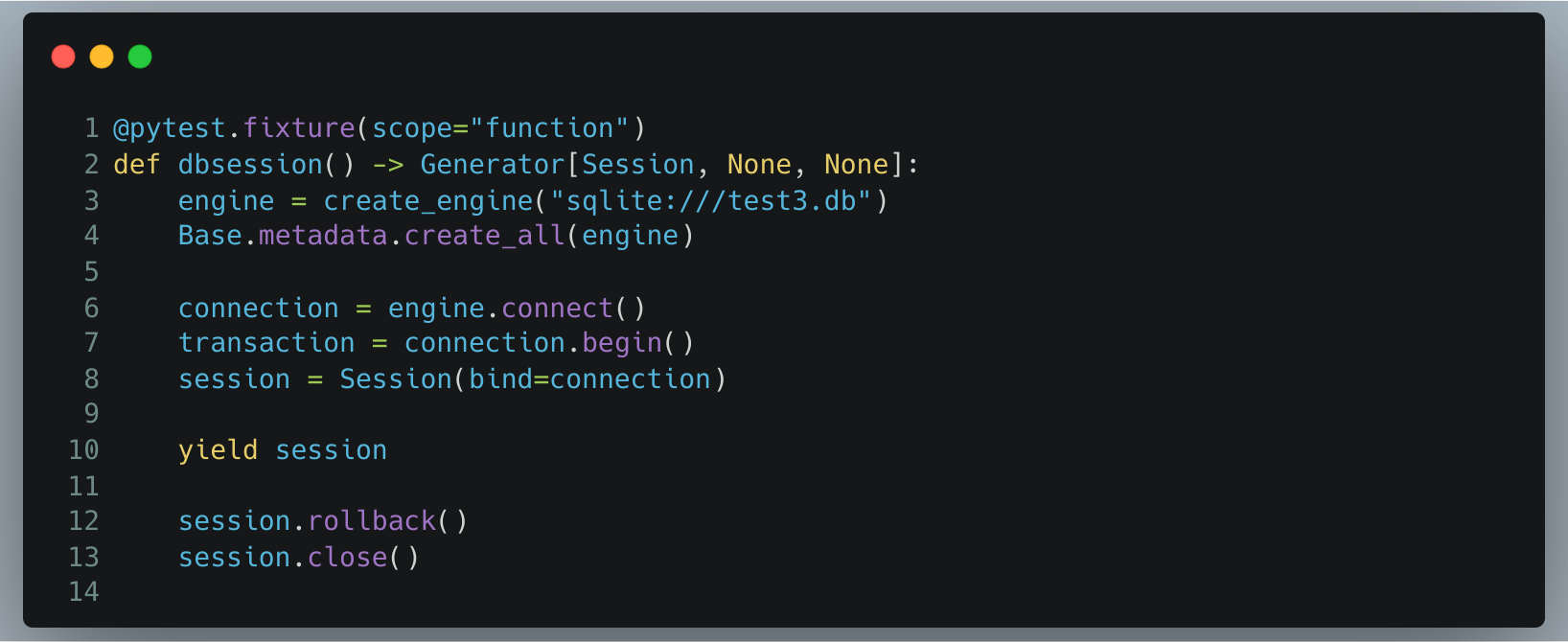
Si vous souhaitez simplement mettre en place le rollback dans vos tests, je vous transmets ci-dessous la fixture telle qu’elle est préconisée dans l’article :
Si vous appréciez la newsletter StuffAndCode, vous pouvez vous inscrire afin de ne manquer aucun article !
🐍 Et recevez en PLUS, un article exclusif sur comment profiler n’importe quel type de code Python.
3) Drop la base de données
Pourquoi ne pas tout simplement créer et supprimer la base de données lors de chaque test ? Ca nous permettrait d’être sûr d’avoir un environnement propre !
Nous pouvons mettre en place ce mécanisme comme vous pouvez le voir ci-dessous.
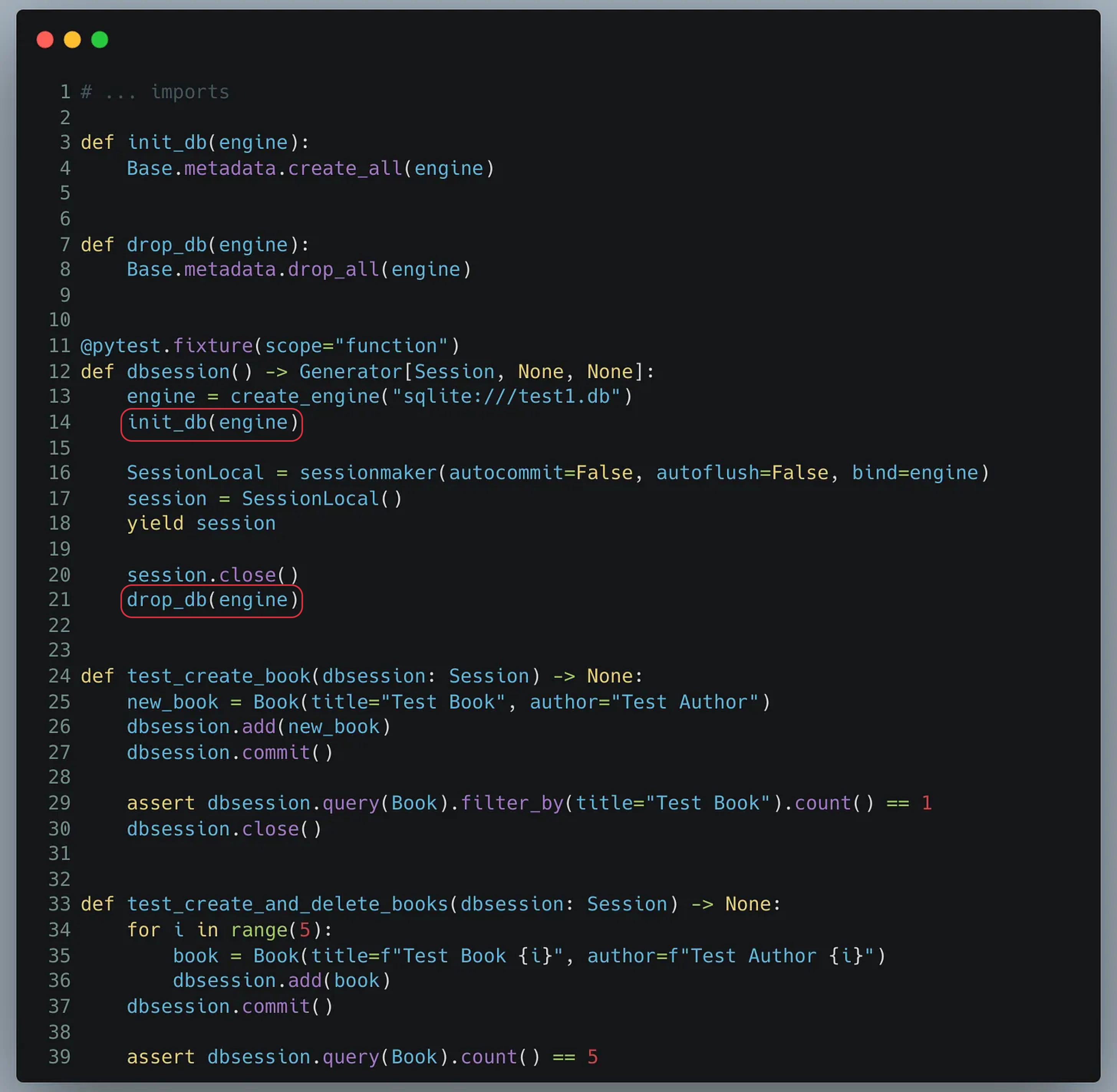

Nos tests passent, c’est bien. Mais à cette approche, incombent certains problemes.
3.1) Les problématiques de cette approche
Supprimer et recréer la database pour chaque test prend du temps, et cela peut rallonger considérablement le temps d’execution de vos tests.
Si vous parallelisez vos tests, cela veut également dire que lorsqu’un test va terminer, il va modifier les données et polluer un autre test, également drop la base de données, pendant que les autres tests finissent de s’executer. Ce qui va générer des erreurs:
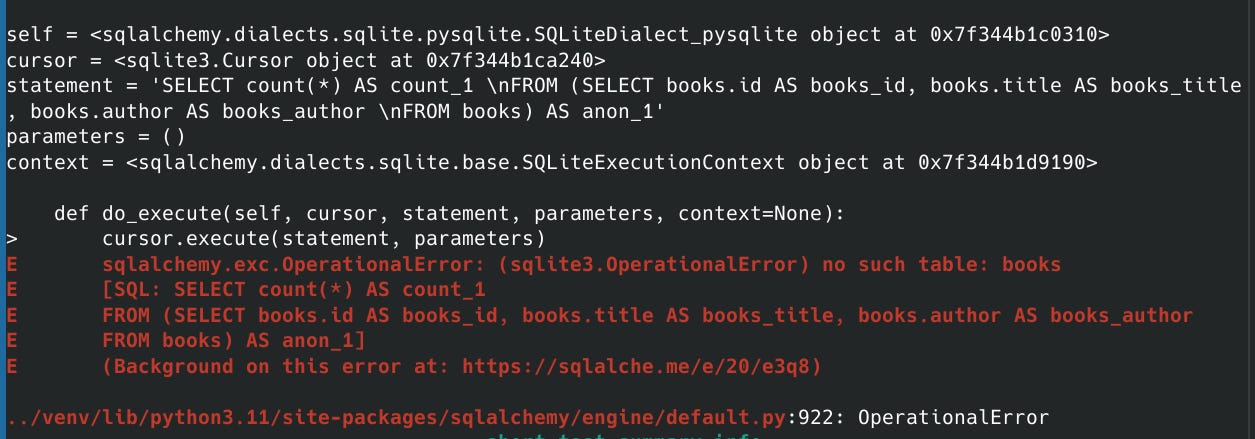
3.2) La Solution : Créer une base de données par worker
Lors de l'utilisation de Pytest-xdist, un nouveau problème émerge : si chaque test parallélisé tente de modifier la même base de données, des conflits surviendront inévitablement.
La solution réside dans la modification de notre fixture de base de données pour créer une base distincte pour chaque worker. Ainsi, chaque worker opère sur sa propre base de données, et évite les conflits tout en bénéficiant d'un véritable parallélisme.
Pour ce faire, pytest-xdist ajoute une variable d’environnement “PYTEST_XDIST_WORKER” qui attribue une valeur pour chaque worker. Par exemple, si nous avons 10 workers, chaque worker aura une variable PYTEST_XDIST_WORKER qui vaudra 0, 1, 2 … 9.
Nous pouvons donc créer une base de données pour chaque worker en nous servant de cette variable d’environnement, résultant en un environnement isolé pour chaque worker.
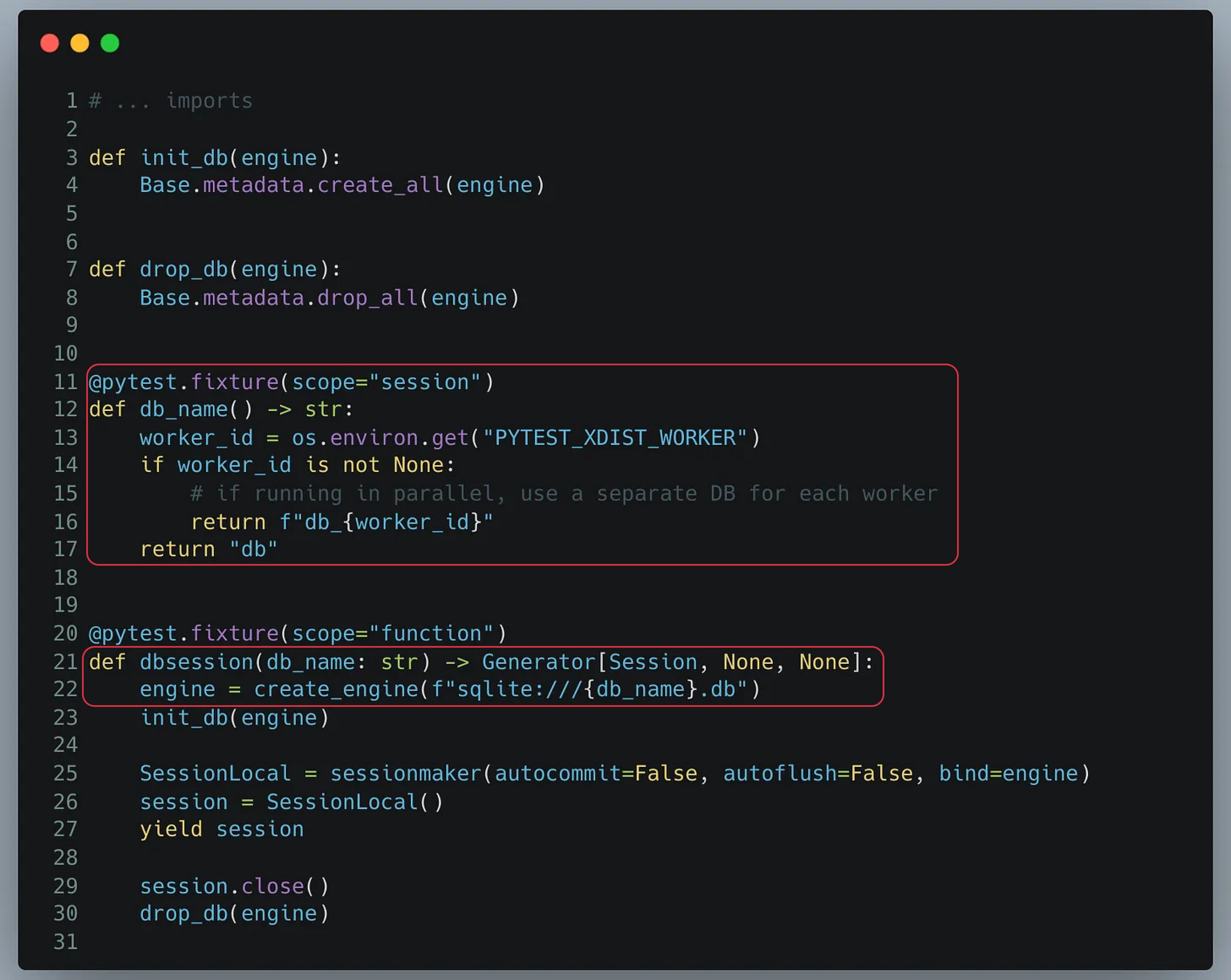

Cela fonctionne !
Cependant, vous pouvez noter que le temps est tout de même passé de +3s contre 0.23s pour la version séquentielle. La raison ? Démarrer les tests sur plusieurs CPU prend du temps !
Donc si vos tests sont déjà trés rapides de manière séquentielle, il est peut-être plus pertinent d’éviter de mettre en place la parallélisation.
A l’inverse, si vos tests sont plus longs, le gain de temps peut-être vraiment très intéressant.
Quizz Time
Quelle librairie utilisons-nous pour paralleliser nos tests ?
Dans quel cas est-il préférable de ne pas paralleliser les tests ?
Quels sont les avantages et inconvénients de drop la database entre chaque test ?
Si vous appréciez la newsletter StuffAndCode, vous pouvez vous inscrire afin de ne manquer aucun article !
🐍 Et recevez en PLUS, un article exclusif sur comment profiler n’importe quel type de code Python.
C’est une bonne idée de paralleliser, je fais jamais ça. Je viens de tester sur un projet pro et ça a réduit par 5 le temps des tests 😃 à voir au déploiement, je vais voir avec les collègues. je peux te faire un retour si besoin
Salut, c’est pas très réaliste comme use cases. Tu test pas vraiment des méthodes tu fais juste du code en utilisant une entité. Je fais rarement des tests mais je crois que ça marche pas comme ça. Et il me semble qu’on peut aussi mocker une db « in memory » qui serait plus performant pour tester qu’une vrai db. C’est aussi beaucoup mieux pour la CI CD, plus simple
En tout cas c’est intéressant j’aurai pas pensé à utiliser mes CPU pour accélérer les test, mais sur une CICD y’a rarement plusieurs CPU. Je pense qu’il vaut mieux aller sur d’autres méthodes